As an offshoot of some other work-related thing I probably won’t end up using, here’s a revival of an old sketch from WT2, marginally refitted for p5.js:
Your daily grind of vision lecturing will be back all too soon.
As an offshoot of some other work-related thing I probably won’t end up using, here’s a revival of an old sketch from WT2, marginally refitted for p5.js:
Your daily grind of vision lecturing will be back all too soon.
Signals from the retina — finally — travel out from the eye along the optic nerve — through the blind spot — and head to the brain for really quite a lot more processing. Much of which, if we’re honest, is not very well understood at all.
The first major stop along the visual pathway is the optic chiasm, a sort of traffic intersection where the signals from both eyes come together, only to be split up and shipped out in different company. The signals from the nasal half of each retina — ie, the side closest to the nose — cross over to the other side of the brain, where they join the signals from the temporal half of the other retina — the side closest to the temple. Image formation in the eye, like any camera, flips up-down and left-right. So the nasal retina of the left eye captures the left hand side of the field of view, as does the temporal retina of the right eye, while the right nasal and left temporal retinas capture the right hand side of the field of view.
From this point on, the visual information is grouped according to which side of the world it’s coming from, rather than which eye. Everything over on the right hand side of the world gets routed to the left hemisphere of the brain, while everything on the left hand side of the world gets routed to the right hemisphere. Each hemisphere still keeps track of which eye each of the signals for its half of the world originated from, but in a real sense it just loses sight of the whole other half of the world. (It’s actually a bit less than half — there’s some shared space in the middle that gets covered by both sides of the brain.)
The hemifields from each eye overlap quite a bit, but between them they cover more territory than either individually. Only the nasal edition has a blind spot, for example — one of the reasons we are almost never aware of this hole in our vision is that it can be filled in from the other eye. Though the more fundamental reason is that our brain doesn’t want us to be aware, and it is 100% calling the shots.
Because the eyes are spatially separated, they see things from a different angle. (Your life is a sham, etc. If I were properly committed to the pre-rec version of this lecture, which rest assured I am not, I would probably have to drag up at this point for a stupid 2 second Zaza insert. Y’all ain’t ready. Fortunately, neither am I.) Comparing and contrasting the two views is super useful for stereoscopic depth perception, so it makes sense to bring them both together for visual processing. The half view split is really quite unintuitive, though, and it can lead to some apparently strange pathologies.
If you lose — or for whatever reason start without — sight in one of your eyes, your field of view will be a bit more limited, as will your depth perception, but both sides of your brain will still be processing both halves of the world and you’ll perceive both left and right. But if the visual processing pathway on one side of your brain is disrupted, downstream of the optic chiasm — say by a stroke or traumatic brain injury — then your ability to see that half of the world may be impaired as well. This is hemianopsia — sometimes hemianopia — or half blindness. In this condition your eyes still work just fine, capturing images like everyone else’s. You’re still sensing both halves of the world, but you can’t perceive one of them.
After the optic chiasm, the visual signals travel to the the thalamus, which is kind of the main routing hub for sensory information coming into the brain; specifically to the LGN or lateral geniculate nucleus — nuclei really, since there’s one each side. Exactly what perceptual processing goes on there is not known for sure, but importantly the LGN doesn’t just take feedforward sensory input from the eyes, it also takes feedback input from further along in the visual system — indeed, there are more feedback connections than feedforward.
One of the things the LGN is believed to do is to take a kind of temporal derivative of the visual information — comparing it with what was previously seen and picking out changes, in a sort of analogue of the spatial differencing performed in the retinal ganglion cells. Again, we’re fine tuning for salience and novelty is interesting.
Another of the things the LGN is thought to be doing is applying some attentional filtering — selecting some aspects of the visual signals and deselecting others to focus in on what we’re especially interested in perceiving right now — what we’re paying attention to. Unlike the relatively static processes of change detection, this kind of selectivity is dynamic — it’s not always picking out the same features, it varies from moment to moment, depending on what we’re doing and thinking at the time. Some of those feedback signals from the cortex are saying, in effect: “boring, boring, meh, boring, whoa hang on a second there buddy, tell me more”. And the LGN does.
All of this is still happening at a pretty low level — tweaking nerve firings corresponding to tiny patches of space and moments of time, not yet assembled into objects or events, not yet translated into knowledge or behaviour. But these fragments are the matter of visual perception, and yet again we see that the brain is right there in the mix at every stage, exerting itself, sifting and organising, amplifying and attenuating, making connections and also, whenever necessary, making stuff up.
Photoreceptor neurons, whether rods or cones, either release glutamate or they don’t, there’s no middle ground. They are not equally responsive to light of different wavelengths, but the wavelength isn’t captured by the output, it’s just a yes/no kind of deal. Collectively, the pattern of releases from such a neuron tells you whether it is being stimulated more or less strongly, but it doesn’t tell you if the stimulation is strong because it’s at a wavelength the neuron is more sensitive to or just because there’s a lot of light — the releases would look the same either way. To be able to separate those cases, we would need more information. Fortunately, at least for most of us, more information is available.
The spectral responses of the different kinds of photoreceptors are illustrated below. (Note that each curve’s vertical extent is normalised so the peak sensitivity is at 100% in each case — rods are still way more sensitive that cones, but we don’t need to care about that right now.)
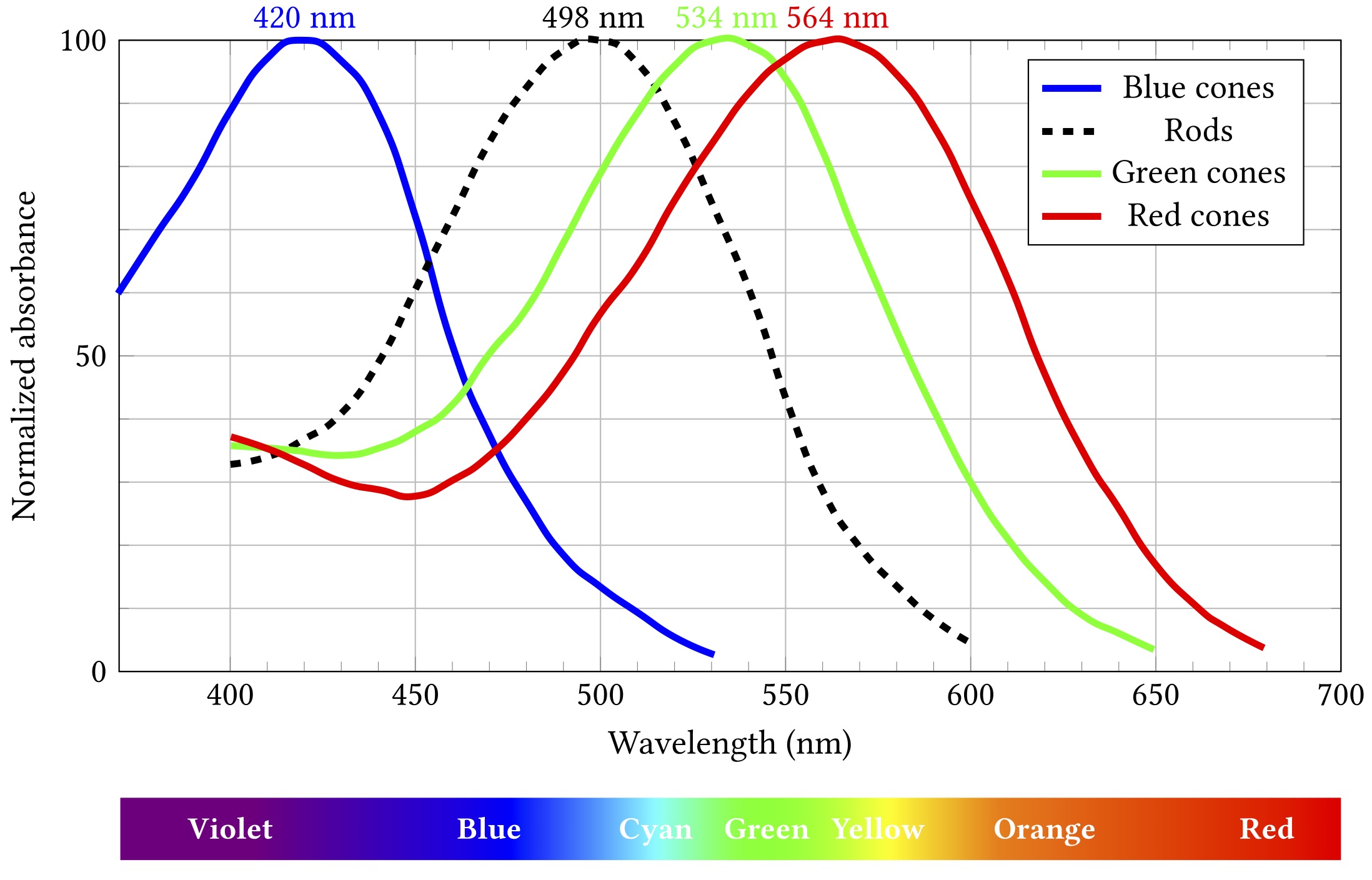
Importantly, while all rods have the same sensitivity, cones come in three different flavours with different absorption spectra. These flavours are sometimes termed blue, green and red, as in the diagram, but are also more accurately, if less picturesquely, known as short, medium and long. If cones of all three types are illuminated by light of the same colour, they will exhibit differing responses — and the differences can be used spectroscopically to determine what colour the light was.
At least, kinda.
Let’s say some blueish light of about 480 nm comes along:
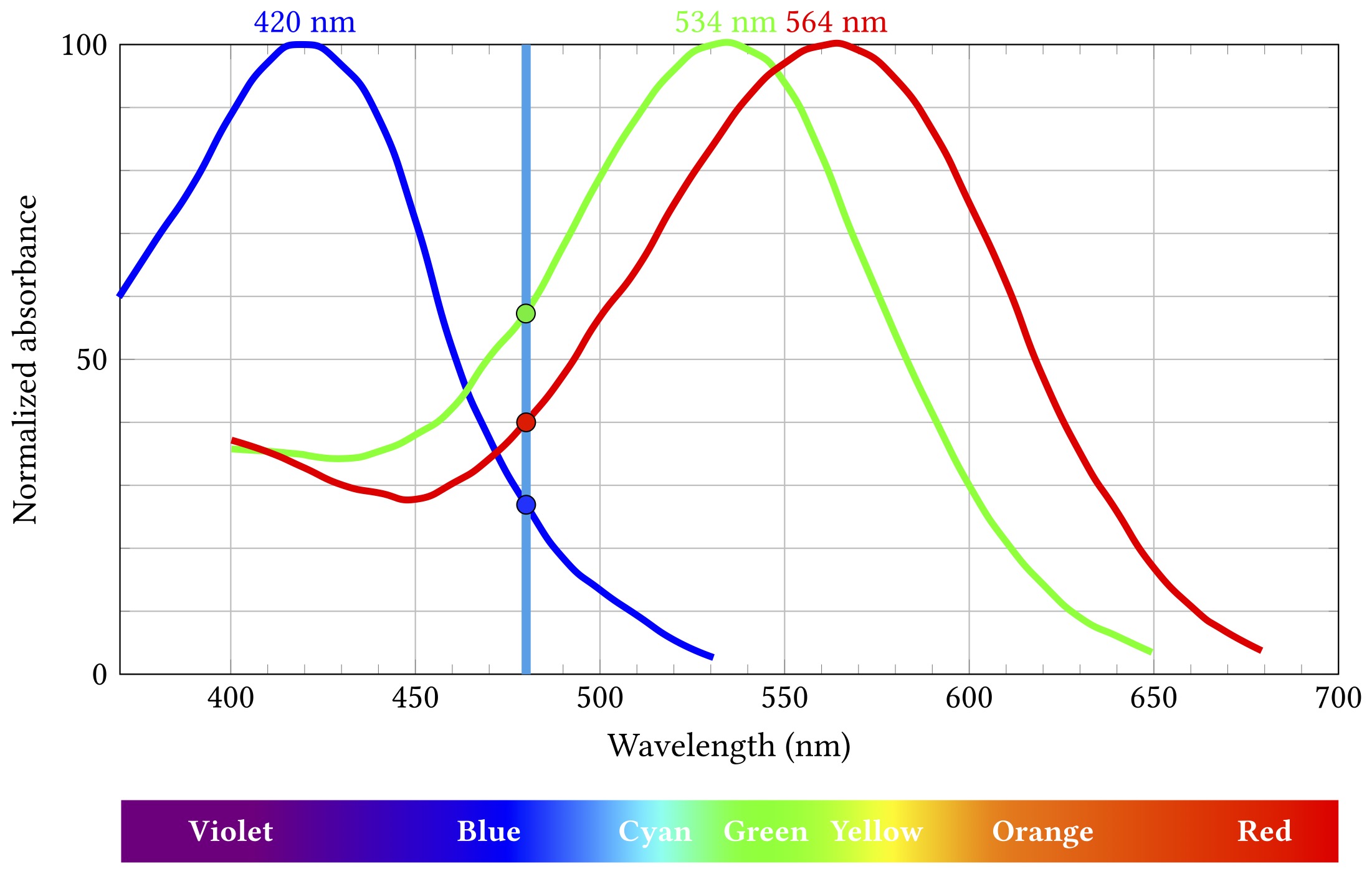
The short wavelength “blue” cones are actually stimulated least by this light, the long “red” cones a bit more, and the medium “green” ones most of all. Importantly, this particular combination of relative stimulation levels does not occur for any other wavelength, and so we can infer that the incoming light is that blueish 480 nm.
Except.
I mean come on, you’re reading this on an RGB screen, how much surprise can I honestly expect to milk out of it?
That uniqueness of inference only works if we know the light is all the same wavelength. That is almost never true, but it’s not a horribly misleading assumption when what you’re seeing started off as broad spectrum white light from the sun and then bounced off a bunch of objects that absorbed a lot of those wavelengths and just left some narrow band to hit your eyes. Which would mostly have been the case most of the time for most of the history of life on Earth. So it’s a pretty decent model for evolution to have hardwired into our biology.
Obviously these days we spend rather a lot of time looking at light from artificial sources for which the model doesn’t hold at all. But — and this is really pretty fortunate for a big chunk of modern human culture and technology — our visual system is still stuck on the veldt, looking for lions or whatever. We can bamboozle it with cheap parlour tricks — and we have gotten really good at those tricks.
You all know how this works: take three different light sources that mostly stimulate the long, medium and short cones respectively. Call ’em, oh I don’t know, red, green and blue? Shine them in the right proportions on your eyes and behold: suddenly you’re seeing orange or turquoise or mauve. Those wavelengths aren’t actually there — does mauve even have a wavelength? — but that doesn’t make your perception of them any less real.
We call these ingredients primary colours, but in what sense are they primary? There’s nothing special about red, green and blue from the point of view of light. Wavelengths don’t mix to make other wavelengths. Violet light is violet, it’s not some mixture of blue and red. Except: what is violetness anyway? As noted back in part 2, colour isn’t a property of light, it’s a perceptual property. I can confidently assert that 425 nm light isn’t a mixture of red and blue, but violet is whatever I see it is.
So primary colours really are primary, in the sense that we can use them to stimulate the perception of (very roughly speaking) any other colour, including some that don’t really exist in the visible spectrum at all. Their primariness — like colour itself — is a product of our physiology and neural processing.
Sing out, Louise. You’ve heard this song before, you probably know the words by now.
And you also know this one: the mechanics of visual perception are complex and fragile and things can go awry.
Colour perception is not universal and you cannot rely on everyone perceiving colours the same way you do — whatever way that is. Various mutations affect the cone cells, leading to a variety of colour vision deficiencies — from somewhat attenuated ability to distinguish between some colours to (rarely) complete monochromacy. These mutations are often sex-linked — ie, the affected proteins are on the X chromosome — so they run in families and mostly affect males.
This can be a problem because colour is a really handy and widely used design feature and popular carrier of meaning. Red means stop, green means go, yellow means go really fast. If you’re constructing an interface or visualising data, you’re probably going to want to put colour to work. Just consider the graphs above — colour is the key distinguishing feature of the three cone lines. So it’s a teensy bit problematic that up to 8% of the men reading this (pretend for a moment than anyone is going to read this) might struggle to tell two of them apart.
(Okay, yes, I’m wrapping this chapter with a rhetorical flourish and it’s really a lie — those particular lines are distinguishable by luminance as well as colour, so 8% of men will probably muddle through — but the point stands more broadly, just go with it.)
The retina is the thin tissue layer on the inside rear of the eyeball that is responsible for transduction of incoming light into electrochemical neural signals and also for several additional integration and processing steps on those signals. It is emphatically not just a simple sensor and indeed is considered to be part of the central, rather than peripheral, nervous system — an extension of the brain.
The retina is organised depthwise into several functional layers containing different types of neurons. These layers are inverted in humans and other vertebrates, meaning that processing proceeds from back to front. Light passes through all the layers, is then detected, and then the transduced nerve signals propagate back up through the layers, getting combined and filtered along the way. The results of all that processing then get delivered to the brain, but note that at that point we’re all the way to the front of the retina — the opposite side from the brain — so the top layer axons — the output cables that go to make up the optic nerve — need to pass back through the retina, making a hole with no detectors — the blind spot.
There are two different types of photoreceptive neurons in the back layer, known as rods and cones after the shapes of their outer segments (the bit of the cell where the actual photoreceptors live). These differ in their spatial distribution and connectivity and in their sensitivity to light — we’ll come back to this shortly.
Unusually, the rods and cones are depolarised at rest — that is, in the absence of a light stimulus the voltage difference across their membrane is relatively low, causing the neuron to release its neurotransmitter — glutamate — frequently. Incoming photons interact with photosensitive proteins in the outer segment, inducing a conformational change that in turn causes a cascade of signalling events that lead to hyperpolarisation of the neuron, making the interior more negative, which reduces its glutamate release. The changing release rate is received and processed by the next layer of neurons, the bipolar and horizontal neurons, and passed on in turn to the uppermost layer of retinal ganglion and amacrine neurons, which aggregate and process the visual information further before sending the resulting signals onward to the brain.
The rods and cones are distributed extremely non-uniformly over the retina. There’s a small area in the centre of the eye’s field of view known as the fovea, which contains only cones, no rods at all, and they’re packed in very densely. Outside the fovea there’s a mixture of both rods and cones, with the rods dominating almost everywhere — there are lot more rods than cones overall, of the order of 100 million compared to a mere 6 million or so cones. Both types become much sparser towards the periphery, and of course in the blind spot, which is about 20° nasal of the fovea, there are none.
In total there are about 100 times as many rods and cones as there are ganglion cells, so the signals going from the ganglions to the brain for visual processing can’t be just one-to-one reportage of the raw light detection. Rather, the data are summarised and transformed to pick out features of interest or smooth out noise or amplify weak signals. This funnelling of the photoreceptor signals into aggregated ganglion outputs is known as convergence — multiple photoreceptor neurons converge on each ganglion cell — and again it is not at all uniform across the eye. Rods in the periphery exhibit high convergence, with a single ganglion cell combining signals from hundreds or thousands of distinct receptors, improving sensitivity in those regions at a cost of spatial resolution. On the other hand, the densely packed cones of the fovea have very low convergence, preserving the fine spatial detail of detection and allowing for much greater visual acuity.
Rods are much more sensitive to light than cones. In bright conditions the cones respond strongly, allowing fine detail to be observed. But in dim conditions the fovea is pretty unresponsive, and vision is dominated by the high convergence periphery, meaning the acuity is much lower, and some objects may not be picked up by central vision, becoming only visible from the corner of your eye. Spooky!
Cones are also responsible for colour detection, as we’ll discuss next post, whereas rods do not distinguish colour — so night vision tends to be pretty monochromatic.
Exposure to light leads to desensitisation of the photoreceptors because the photosensitive pigments that do the detection are bleached in the process. These are continually replenished, but the process takes time. So the overall sensitivity of the retina is not fixed, it depends on how much light has been seen lately. If you’ve been out in bright daylight and go into a dark room, your sensitivity will have been depleted by the brightness and you won’t be able to see well. Whereas if you’ve been in the dark a long time, your receptor population will be fully replenished and you’ll have maximum sensitivity. This replenishment is known as adaptation — the eye has adapted to the darkness and is better able to see. Subsequent exposure to a lot of light will once again bleach the receptor pigments and reduce sensitivity. The time course of adaptation comes from the interplay between the rate of bleaching and the rate of replenishment.
As well as just aggregating the incoming signals, ganglion cells also pick out local spatial features, in particular brightness differences — edges — within the patch of retina whose photoreceptor cells that converge onto them. This patch is known as the receptive field — the region of the incoming image to which the neuron is receptive. (This concept is not limited to ganglion cells and we’ll encounter it throughout the processes of visual perception.)
Most retinal ganglion cells exhibit a centre-surround organisation to their receptive fields, whereby the response of the ganglion cell depends on the difference in activity at the centre of the receptive field and that in the surrounding region. The mechanism for this is lateral inhibition — the signal evoked by one region of photoreceptors is inhibited by the the signals from its neighbours. Ganglion cells may be off-centre — responding maximally to a dark middle and bright surround — or on-centre — responding to a bright centre and dark surround.
This kind of feature extraction isn’t a physiological necessity — the neurons could be wired up in arbitrary other ways. It’s a matter of perceptual utility. Edges are potentially important markers of stuff happening in the world — where one object begins and another ends. They represent things we might want to interact with, or run away from. Regions of uniform illumination evoke less response, because in some sense they are less perceptually interesting.
Once again, we note that perception is an active, cognitive process, rather than a passive consumptive one. Even before we leave the eye we’re already sifting and selecting and making value judgements.
A basic camera consists of an aperture to control the amount of light getting in, usually adjustable by means of a diaphragm, a lens or system of lenses to capture and focus the light, and some form of chemical or electronic detector — all wrapped up in a dark box or chamber — from which the term camera comes — to stop light getting to the detector other than through the aperture & lens. All of these elements are also present in the eyes of many animals, including us.
The eye’s aperture is the pupil, adjusted by the sphincter and dilatory muscles of the iris to let in more light in dim conditions, less when it is bright.
The eye has two lens elements. The more rigid, fixed focal length cornea does the bulk of the focusing, while the softer, deformable lens provides adjustability. A ring of ciliary muscle around the lens can contract to increase the lens curvature, decreasing its focal length and allowing nearer objects to be in focus. This reshaping of the lens is known as accommodation.
The distances that an individual can bring into focus range from the far point, when the ciliary muscles are fully relaxed, to the near point when they are maximally contracted. These distances depend on the shape of the eye, the focusing power of the cornea and lens, the deformability of the lens and the strength of the ciliary muscles.
Impairments of focal range are very common. People with myopia or nearsightedness can’t focus on distant objects — their far point is significantly nearer than infinity and light from beyond that point comes to focus in front of the retina. Those with hyperopia or farsightedness can’t focus on nearby objects, the light from which comes to focus behind the retina. Both of these conditions can be corrected with glasses or contact lenses, introducing extra focusing elements in the optical path to change the baseline focusing power of the whole system. As people age, their lenses become increasingly stiff and their ciliary muscles weaken, reducing their capacity to accommodate, shifting the near point further away. This age-related farsightedness is known as presbyopia, literally “old eye”, and it’s why so many people need reading glasses as they get older.
Eyes are directional and there are several other sets of muscles connecting the eyeball to its socket that enable eye movements of various kinds — importantly, these movements are generally coordinated for both eyes. The types of movement include:
Notably, most of these movements are not under conscious control. You can choose to look at some location, but you can’t choose to point your eyes in arbitrary directions independent of one another, or rotate your eyes about their view direction, or contract your irises. You can make your gaze trace a path in a series of saccades, but for smooth pursuit you pretty much need to watch something that’s actually in motion and let your brain move your eyes automatically. You can — just about — voluntarily shift focus or vergence, but it’s much much easier when you have some actual object to focus on, or at least can clearly imagine one.
Already we can see that the brain is imposing a huge amount of structure on the processes of vision that we just take for granted, and these percolate all the way through our visual perception. Things like saccades and the vestibulo-ocular reflex define the subjective experience of seeing — chopping up and smoothing out the world like a slick Hollywood production team, not some rough Blair Witch shakycam. And this is still just at the stage of the mechanics of light capture. We haven’t even got to the point of transduction yet. To do that, we need to talk about the eye’s detector component: the retina.